接著我們使用 ptt電影版當作例子
網址:https://www.ptt.cc/bbs/movie/index.html
每篇文章都有標題我們希望用程式抓取這些資料
如果我們使用前面網路連線的方法,可以看到被禁止無法使用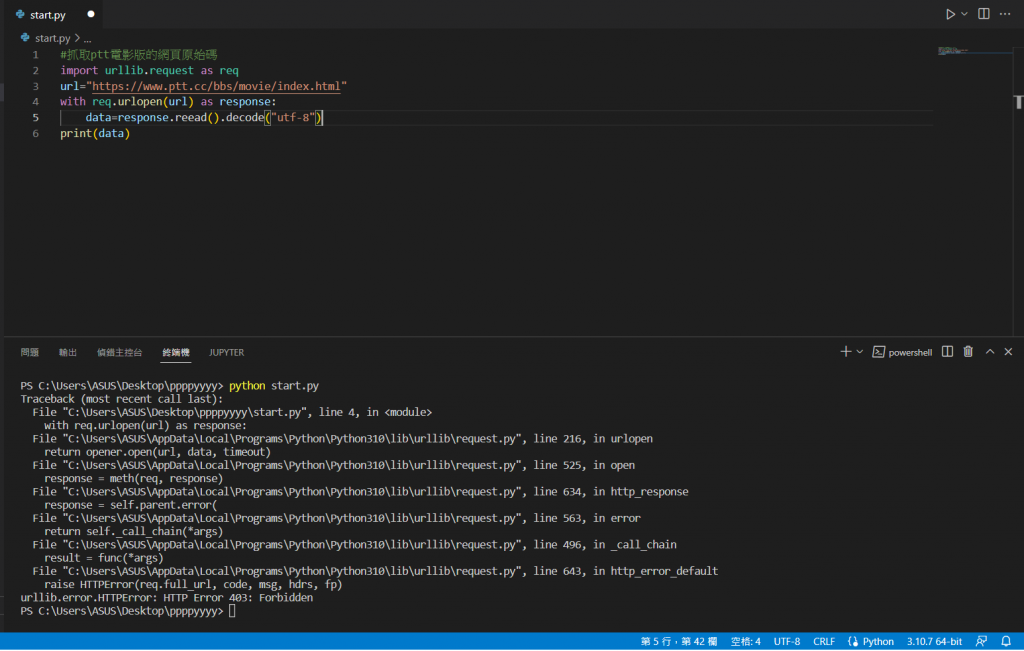
到ptt網頁監控工具可以看得這個列表(按下f12後選取network)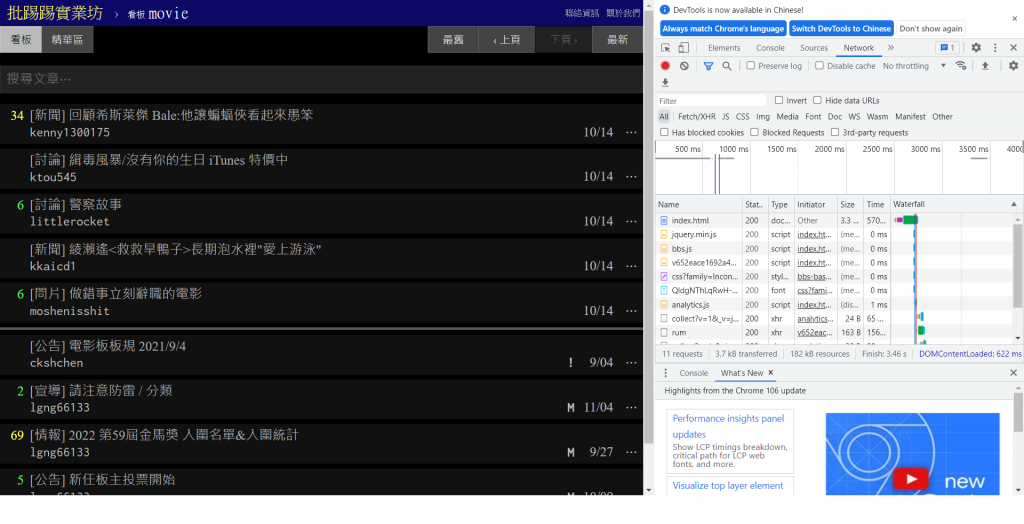
這是一般使用者進入網站會發送的訊息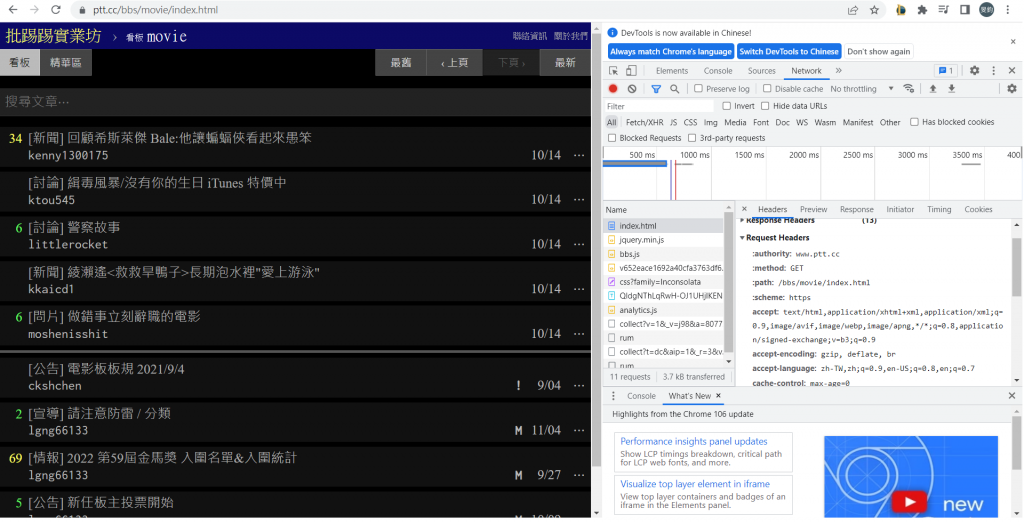
我們需要讓我們的程式也發送這些訊息才不會被禁止使用
建立一個requset物件增加剛剛的 user-agent 讓我們的程式像是一個使用者進入,這樣就可以成功抓取網頁前端的程式碼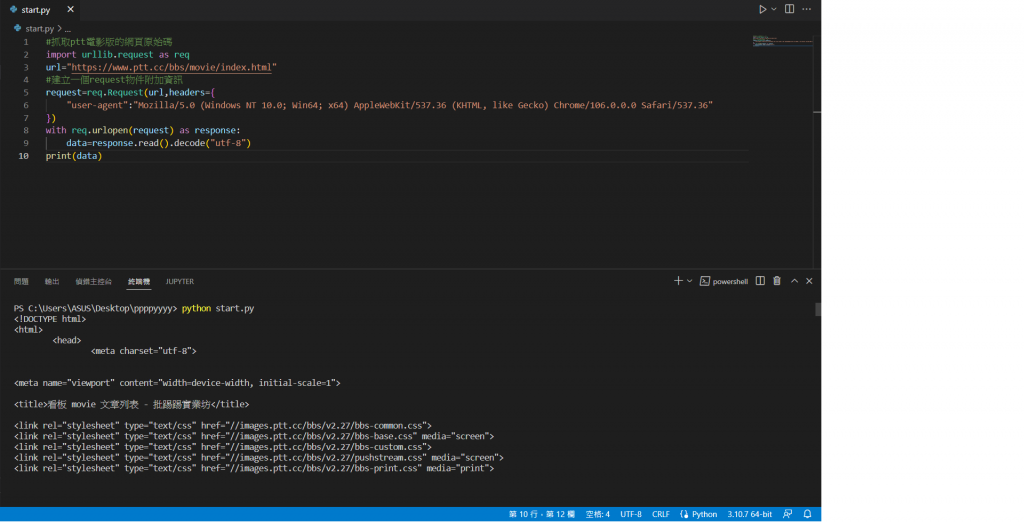
使用find它可以幫我找到一個符合要求的標籤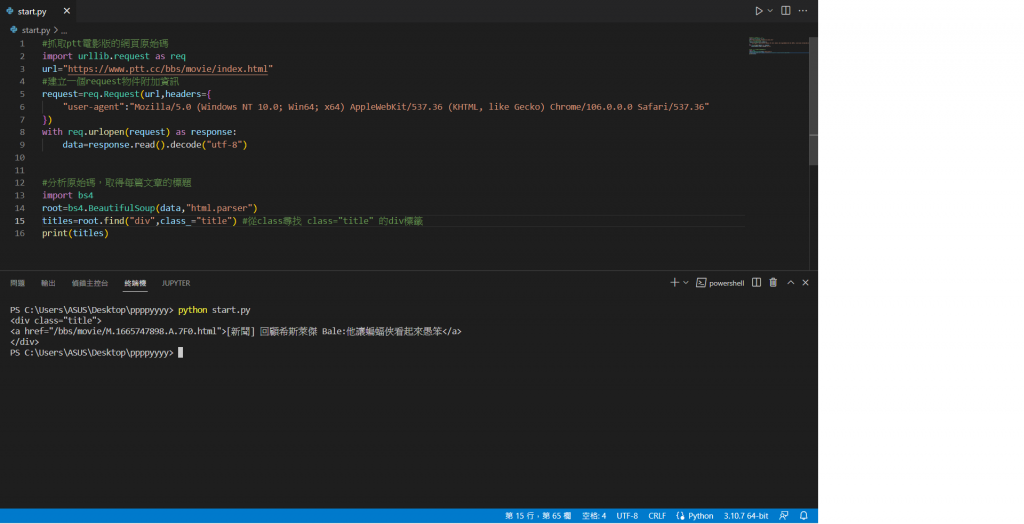
使用find_all可以抓取全部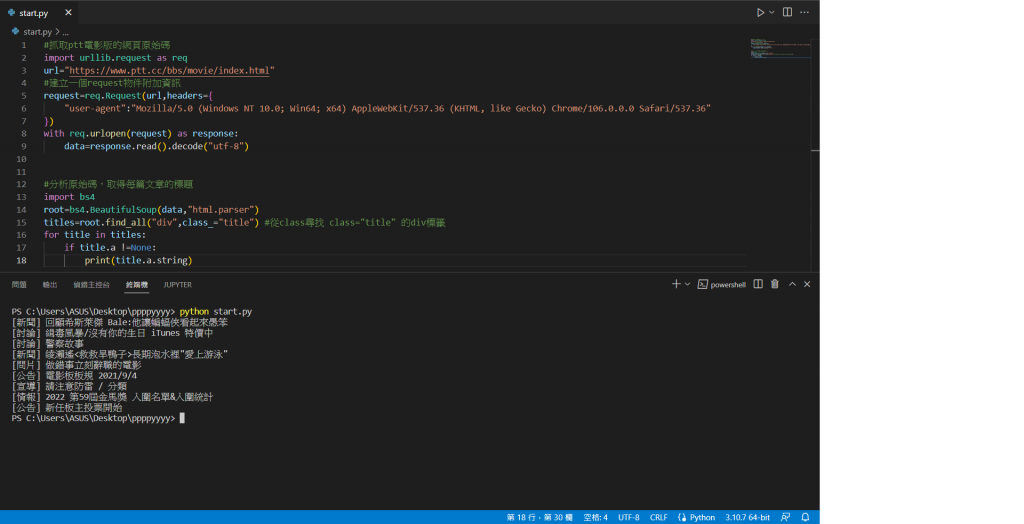
參考來源:https://www.youtube.com/watch?v=9Z9xKWfNo7k&list=PL-g0fdC5RMboYEyt6QS2iLb_1m7QcgfHk&index=19
 409261275
409261275

 iThome鐵人賽
iThome鐵人賽